

【TOPPAN GENERATIVE TRIAL#8】 生成AI技術動向・未来予想

第1回ワークショップ 発表内容(TOPPAN研究者:酒井 修二)
こんにちは。TOPPANデジタル酒井です。
TOPPANデジタルでは、生成AIに関する様々な取り組みを行っております。
その中でも新たな試みとして立ち上げたのが、CHAOSRU INC. と共同で展開する実験プロジェクト『TOPPAN GENERATIVE TRIAL』です。
これまでの記事で、プロジェクトの詳細、2024年8月8日に開催されたワークショップのレポートをお送りしました。
【TOPPAN GENERATIVE TRIAL#1】WELCOME
【TOPPAN GENERATIVE TRIAL#2】第1回ワークショップ開催レポート
【TOPPAN GENERATIVE TRIAL#3】AIと模索する新たな創造性
【TOPPAN GENERATIVE TRIAL#4】生成AI×エンタメの未来
【TOPPAN GENERATIVE TRIAL#5】将来のクリエイティブワークフローを探る
【TOPPAN GENERATIVE TRIAL#6】エンジニアは映画を作れるか
【TOPPAN GENERATIVE TRIAL#7】生成AIによるプロモーション動画
今回の「TOPPAN GENERATIVE TRIAL#8」では、ワークショップの詳細レポート第6弾として、私、酒井の発表をご紹介します。
(本レポートは、2024年8月時点での情報を発表した内容になります。生成AI関連の技術進歩は著しく、本レポート公開時の状況と異なる内容も含まれます。)
【発表者紹介】TOPPAN研究者:酒井 修二
TOPPANデジタル株式会社 所属。博士(情報科学)。画像処理・3Dビジョン研究を専門に、画像生成AI研究に従事。2015年 映像情報メディア学会 丹羽高柳賞論文賞受賞。2023年 SSII 最優秀学術賞受賞。「使っていて“面白い”生成AI技術をつくる」ことをテーマに活動中。
【発表内容】生成AI技術動向・未来予想
生成AIを取り巻く環境
2023年~2024年は、画像・動画生成AIにおいて、非常に大きなターニングポイントとなりました。画像・動画生成AI技術の爆発的な発展により、世の中に大きな影響を及ぼしました。例えば、AIによる生成作品が、絵画や写真のコンテストで入賞するなど、これまで専門家が担ってきた創造的な活動の一部が、生成AIによって実現されるようになってきました。それに伴い、アーティスト・クリエイターからの不満や、生成AIの取り扱いについて、議論を生んでいます。また、技術発展の良い影響として、画像・動画生成AIの活用例が世の中に出始めました。例えば、AIタレントを起用したCMや、画像生成AIを駆使して制作したCMなどが、公開されました。このように、生成AI技術の発展は、映像作品制作・コンテンツ制作に対して、大きな影響を与えます。本発表では、研究者視点で見える、現在の技術発展の方向性と、今後の技術発展の予想について、報告しました。
現在の技術トレンド:研究分野での技術発展の方向性
①画像生成
私は、単純に画像をつくるだけであれば、「発展のピークを越えた」と感じております。拡散モデルと呼ばれるディープラーニング技術の適用により、画像生成AIの精度は格段に向上しました。拡散モデルの登場は、現在の、Stable Diffusion、Midjourney、DALL-Eなどの画像生成AIの発展に直結します。今後も、単純な高精度化は粛々と進んでいくと予想しています。
さて、画像生成AI技術のひとつの発展の方向性として、画像生成AIの高速化が挙げられます。例えば、LCM [1]、SDXL Lightning [2]、StreamDiffusion [3]といった技術が挙げられます。これらの技術によって、インタラクティブな用途、つまりリアルタイムでの画像生成AIの活用が広がっています。また、リアルタイムでの画像生成AIの実現は、インタラクション技術の研究分野での画像生成AIの活用にも繋がっていきます。
別の発展の方向性として、テキスト(プロンプト)以外の生成制御技術が挙げられます。例えば、ControlNet [4]、IP-Adapter [5]などが代表的なものです。ControlNetでは、エッジ画像や深度画像(画像の奥行きを画素値の明るさで表現したもの)を用いて、制御用画像の構造を保った画像生成が可能です。また、IP-Adapterでは、参照画像のスタイルや雰囲気を、生成画像に継承することができます。このように、画像内の構造・構図や、画像のスタイルの細かい指定など、テキストでは指示しきれない要素も、画像生成で扱うことが可能になりました。また、これらの技術は、画像のスタイル等について、複数の画像間での一貫性を保つことにも使えるかもしれません。
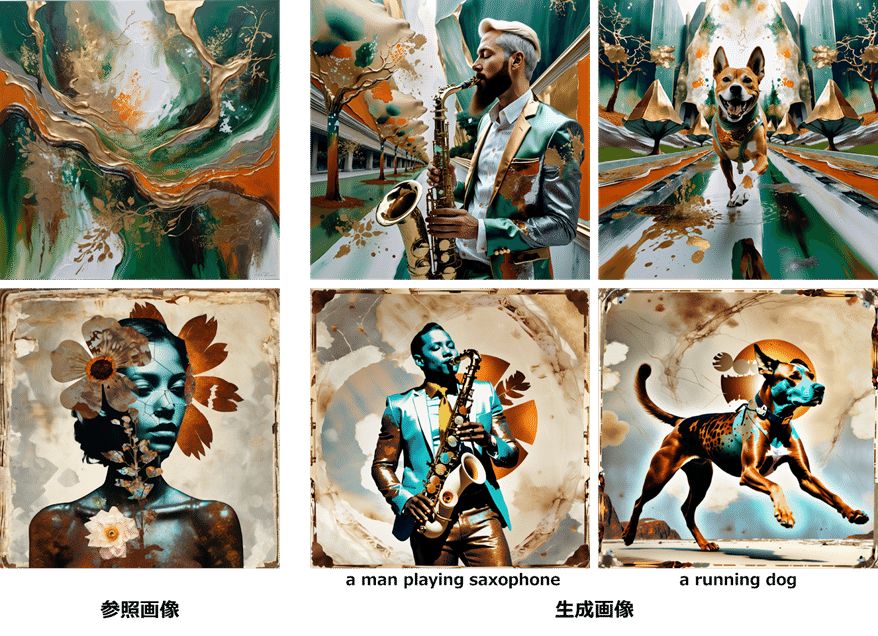
もうひとつの発展の方向性として、生成AIによる画像編集が挙げられます。例えば、IC-Light [6]という技術では、画像のライティングを生成AIを使って編集できます。ほかにも、FreeDrag [7]という技術では、画像内の物体をドラッグし違和感なく編集することが可能です。このように、画像生成AIは、画像をいちから作るだけでなく、画像を編集するタスクでも利用されるようになっていくかもしれません。
IC-Lightによるライティング編集の例
②動画生成
2024年2月にOpenAI社のSoraが発表され、人間が制作した映像と区別できないほどの高品質な動画が生成できるとして、大きな反響がありました。また、その後、Kling、Luma Dream Machine、Runway Gen3と、多くの動画生成AIサービスが発表されております。このように、動画生成AIは、まさに、現在進歩の真っ只中にいるといえるでしょう。学会でも、しばらくは、単純な高精度化・高品質化の方向で技術が発展していくことが予想されます。
③3D生成
私は、3D生成技術は、まだまだ出始めで、発展途上にあると感じています。3D生成研究の主流は、LucidDreamer [8]やTripoSR [9]のような3Dオブジェクトの生成です。一方で、それとは別の方向性として、WonderWorld [10]などの3D空間の生成技術も発展しています。学会発表の件数等をみると、研究分野として、3D生成は非常にホットトピックです。2024年~2025年は、3D生成の発展の年になるのではないかと、感じております。

今後の技術発展の予測
本発表では、10年後の未来を見据えた、今後の画像・動画生成AIの発展の方向性として、大きく2つの方向性を提示しました。ひとつめは、「生成AI単体で生成できるコンテンツが大規模化・複雑化していく」未来です。例えば、30分の動画生成や、高品質な3Dモデル+モーションの生成等です。一方で、このような大規模・複雑なコンテンツの生成では、生成物をテキスト(プロンプト)のみで指示できなくなると予想されます。それを解決するために、①対話型の制御技術や、②絵コンテや脚本といった複雑な生成指示による生成制御技術が発展するのではないかと、予想しております。
今後の画像・動画生成AIのもう一つの発展の方向性は「生成AIがツール化されていく」未来です。既存の処理を置き換えるような生成AI技術は、画像処理アプリのひとつの機能になっていくと予想します。その時には、その機能が生成AIによるものなのか、ユーザは気にせずに使っているかもしれません。
未来を見据えた際、クリエイターが気になるポイントとして、「クリエイターの仕事はAIに置き換わるのか?」という問いかけがあります。これに対する私の回答は、「置き換わらない」です。私の感覚としては、現在の技術発展の延長線では、「作家性」や「センス」といったものが、人間に求められ続けます。技術発展に伴い、AIのみで作られたコンテンツが登場することは容易に想像できますが、それが主流になることはないでしょう。ただし、技術的なパラダイムシフトは状況を一変させます。そして、そのようなパラダイムシフトは、突如としてやってきます。これは、10年前に、今の生成AIの状況を誰も予想できていなかったのと同じです。
また、生成AIの特性から考えたときに、「生成AI×コンテンツ制作」の将来ワークフローはどうなっていくでしょうか。まず、前提として、綿密な設計図通りに生成AIがコンテンツを作ることは難しいでしょう。つまり、クリエイターの頭の中を具現化できるほど、十分な指示を生成AIに与えられません。そのため、生成AIを活用したコンテンツ制作の中では、生成AIのランダム性や自由度を許容した制作過程が求められます。生成AIの生成結果を見ながら、最終的なコンテンツイメージを変更し、徐々に固めていくようなやり方が求められると考えています。
最後に
私は、「使っていて“面白い”生成AI技術をつくる」ことをテーマに研究をしています。ここで、生成AI利用における「面白さ」とは、①技術の精度、②ユーザが創意工夫できる余地、③想定外のAIの挙動の、三つの相反する要素のバランスの上に成り立つと考えています。技術の精度が高くなりすぎると、創意工夫できる余地がなくなったり、AIならではの想定外の挙動がなくなったりします。一方で、想定外のAIの挙動が激しすぎると、ユーザがコントロールしきれなくなります。絶妙なバランスの上に、「面白さ」が成り立ちます。そんな「面白さ」を、本プロジェクトを通じて、クリエイターの皆様と探求していきたいと考えています。
会場と協力について
本イベントは、XRコミュニティ「Beyond The Frame Studio」と「NEUU」の協力を得て開催されました。
NEUU
XR技術の常設体験施設です。XR作品の展示や、イベントや映画祭の企画・開催をされています。
https://neuu.jp/
Beyond The Frame Studio
XRに特化した国際映画祭「Beyond the Frame Festival」をきっかけに誕生したコミュニティです。XRコンテンツ制作に関心があれば、初心者からプロまで参加が可能です。
https://btffstudio.com/
【メンバー募集】生成AI x クリエイティブの未来を一緒に探りませんか?
現在、生成AIに関するディスカッションや、実際に手を動かして検証を進めていけるメンバーを募集しています。コミュニティには約60名のメンバーが参加しており、グラフィック、映像、XRなど、さまざまなジャンルで活動するクリエイター、エンジニア、研究者が集まっています。
生成AIは、あらゆるクリエイティブ活動に大きな影響を与える可能性を秘めています。私たちは、実際にコンテンツを制作しながら、AIの現地点や未来について議論を深め、共に探求しています。生成AIに興味があり、一緒に学び、成長しながら新しい表現の形を追求したい方は、ぜひご参加ください。途中参加も大歓迎ですので、気軽にご参加いただけます。
なお、参加にはDiscordへの登録が必要です。詳細はDiscord内でご確認いただけますので、まずはご登録ください。
参考文献
[1] S. Luo, Y. Tan, L. Huang, J. Li., and H. Zhao, “Latent consistency models: Synthesizing high-resolution images with few-step inference,” arXiv, 2023.
[2] S. Lin, A. Wang, and X. Yang, “SDXL-lightning: Progressive adversarial diffusion distillation,” arXiv, 2024.
[3] A. Kodaira, C. Xu, T. Hazama, T. Yoshimoto, K. Ohno, S. Mitsuhori, S. Sugano, H. Cho, Z. Liu, and K. Keutzer, “StreamDiffusion: A pipeline-level solution for real-time interactive generation,” arXiv, 2023.
[4] L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” Proc. Int’l Conf. Computer Vision, 2023.
[5] H. Ye, J. Zhang, S. Liu, X. Han, and W. Yang, “IP-adapter: Text compatible image prompt adapter for text-to-image diffusion models,” arXiv, 2023.
[6] L. Zhan, A. Rao, and M. Agrawala, “IC-Light GitHub Page”, https://github.com/lllyasviel/IC-Light, 2023.
[7] P. Ling, L. Chen, P. Zhang, H. Chen, and Y. Jin, “FreeDrag: Point tracking is not you need for interactive point-based image editing,” arXiv, 2023.
[8] Y. Liang, X. Yang, J. Lin, H. Li, X. Xu, and Y. Chen, “LucidDreamer: Towards high-fidelity text-to-3d generation via interval score matching,” arXiv, 2023.
[9] D. Tochilkin, D. Pankratz, Z. Liu, Z. Huang, A. Letts, Y. Li, D. Liang, C. Laforte, V. Jampani, and Y-P. Cao, “TripoSR: Fast 3D object reconstruction from a single image,” arXiv, 2024.
[10] H-X. Yu, H. Duan, C. Herrmann, W. T. Freeman, and J. Wu, “WonderWorld: Interactive 3D scene generation from a single image,” arXiv, 2024.