

【数式なし!】データ委員会でKaggleに挑戦した話ー前編ー

1.自己紹介
こんにちは!
TOPPANデジタル株式会社の五十棲です。
初投稿の新参者となりますが、よろしくお願いいたしますm(__)m
私は日ごろ、物流倉庫DXの促進に向けて、LOGINECT®︎の新規開発ツールの提案や物流倉庫のデータ分析業務を担当しています。
日々データ分析業務に奮闘している私ですが、本日は組織のデータ分析力向上のため、データ委員会(後ほどご説明します)の皆さんとKaggleに挑戦した話についてご紹介いたします。
また今回は、数式なし・図をメインに参加内容を解説しますので、お気軽に見ていただければと思います!
2.データ委員会とは?
TOPPANデジタルのICT開発センターには、私の所属しているDXソリューション開発部をはじめとする複数部署が存在しますが、部署横断的に委員会活動が実施されています。
委員会活動は、普段の業務の+αとして「横串連携で各部署のプロダクトや受託開発の促進や付加価値を高めること」が目的です。

私がメンバーの一人として参加しているデータ委員会では、分析に限らず、データインフラ構築やそれらに興味を持つメンバーが参加しています。
委員会ではおもに
週1定例会、自分の興味やテーマに沿った分科会
データに関する相談や疑問を気軽に質問BOXに投稿
興味・知識のレベルに合わせた輪読会 …
などに参加できます。つまり業務の相談はもちろんのこと、データの知識を持った方たちと意見交換ができるというわけです。
最近では、委員会の運用や地盤が整ってきたこともあり、活動で得たスキルや技術・人脈を生かし実務に落とし込むフェーズに突入しています。
3.Kaggleとは?
すでにご存知の方も多いかと思いますが、
Kaggleとは、データ分析の腕を競うデータ分析コンペティションです。
もっともよく知られた分析コンペのプラットフォームともいわれ、
世界中の企業や省庁、研究機関が主催者となって開催されます。
日本では過去に、東京電力グループや株式会社メルカリなどが主催しています。
Kaggle のホーム画面
レベルや目的については、
無料でデータ分析してみたい
Kaggleの称号やランキングを得たい
賞金取りたい!!(賞金は億単位のことも…)
など、参加者次第でさまざまです。
※そのほか、日本発の分析コンペとしてSIGNATE、Nishika などがあります。SIGNATEは、日本国内最大のデータサイエンスプラットフォームとしてDXの人材育成を促進しています。Nishikaは、データプラットフォームを提供し、データサイエンティストと企業のマッチングを促進しています。
4.Kaggle参加の目的
参加したコンペの説明に入る前に、今回データ委員会でKaggleに参加した目的を整理します。
チーム (委員会) 活動の促進、分析技術の社内共有
データ分析のコミュニティへの参加(社外)
Kaggleについて知る(一連の kaggle 操作に慣れる、サブミットへの到達)
ランキング上位を目指す …
前述した通り、データ委員会ではデータ分析に対する経験や興味の度合は人それぞれですが、「委員会で得た知識や技術を、自身の持つプロダクトの価値向上へつなげたい」という思いは共通しています。ただ、口頭での相談や輪読会だけでは活動に限界がありました。また、データ分析を製品に活用するためには、社会で役立つサービスにつなぐことが重要でありそのアイデアが求められます。データ委員会では、その議論の場やトレーニングの機会を増やすべく、同じデータを使ってチームで共闘できる機会を作りたいと考えました。
そこで、各自で可能な限り時間を作ってKaggleに参加し、まずは上記の目的を掲げ、達成しよう、とのことで活動の一歩を踏み出しました。
5.データ委員会でKaggleに挑戦しよう!
ということで、この企画は始まりました。
挑戦したコンペの概要
コンペ名:Home Credit - Credit Risk Model Stability
目的:クレジットカード会社の顧客の債務不履行の予測
期間:2024年2月6日~2024年5月28日
競うもの:予測精度(Gini stability)

このコンペの主催は、オランダにあるHome Credit社という実際に存在する消費者金融業者で、信用履歴の少ない顧客にも金融サービスを提供する会社として知られています。
「信用履歴が少ない=情報の少ない」顧客のデータから、適切に債務不履行、すなわち「お金の返済が滞ってしまう人を予測しましょう」ということが主な目的です。
また少しわかりにくい指標だったのですが、今回コンペでは、「stability」という予測モデルの安定性スコアを競うことになっていました。
私たちでこのコンペを選んだ理由としては、予測分析におけるメジャーなデータ分析であったためで、参加の目的・意図の1つである分析技術の社内共有に適していると判断したためです。
6.分析しよう!
行数:約150万行(train data 約90万, valid data 約30万,test data 約30万)
列数:48列(データ処理されて分析に使用するのはこのカラム数)

KaggleではソースコードのことをNotebookと呼ぶのですが、
PythonとRでいずれかの言語が選択できます。
またこのNotebookをHome Creditのスターター用に公開している方がおり(ありがたい!)、
私たちはまずはそれを使って分析に必要なデータ処理、データの中身、分析や指標を確認しました。
※参考までに以下は、Notebookのタイトル、データ前処理のコードとそのコードに対応する日本語解説の一部になります。

def set_table_dtypes(df: pl.DataFrame) -> pl.DataFrame:
# implement here all desired dtypes for tables
# the following is just an example
for col in df.columns:
# last letter of column name will help you determine the type
if col[-1] in ("P", "A"):
df = df.with_columns(pl.col(col).cast(pl.Float64).alias(col))
return df
def convert_strings(df: pd.DataFrame) -> pd.DataFrame:
for col in df.columns:
if df[col].dtype.name in ['object', 'string']:
df[col] = df[col].astype("string").astype('category')
current_categories = df[col].cat.categories
new_categories = current_categories.to_list() + ["Unknown"]
new_dtype = pd.CategoricalDtype(categories=new_categories, ordered=True)
df[col] = df[col].astype(new_dtype)
return df
データの課題
まず、私の中でこのデータを少し眺めてみて2点気づくことがありました。
欠損データが大量
目的変数の偏りがすごい(債務不履行が極端に少ない)
ということで「1. 欠損データが大量」について対処します。
手始めに分析データを集計してみましょう。
課題1:「欠損データが大量」に対する情報の整理
以下は、すべてのカラムの欠損データの数をカウントした表になりますが、
36個のカラムで欠損が発生しています。
中には全体に占める欠損の割合が8割を超えるものもあり、顧客によって情報量の少ないデータであることが読み取れるかと思います。
また、欠損が極端に多くなっているカラムの内容を見ると、No5の「過去 24 か月間の平均融資額」やNo45-47の「税額控除」などで、融資を受けた直後にすぐにはわからないデータであることも想像ができますね。

それと見落としがちなのが、このデータはcategory型、float型、int型と、データの型が文字列と数値で混在しています。
通常、統計解析の手法を用いる場合は、文字列は数値に変換する必要があるため、処理していないデータをそのままアルゴリズムにかけると、エラーがでてしまいます。
すなわち、このデータは分析の前処理にも骨が折れるデータだということがわかりました。
データサイエンティストの救世主:Light GBM
ここで我々を救ってくれるのが、機械学習アルゴリズムです。
決定木分析は文字通り、ツリー構造で分類や予測を行う分析手法として広く活用されています。

決定木は、ある会社でプロテインを売ろうとして、ターゲティングに迷った際に使用したりする。
たとえばこの結果は「男性」で「近所にジムがある」人は、ほかの集団と比べて購入する確率が92%と高いので、この層を中心に広告をうったりとマーケティング戦略をたてることに活用する。
標題にありますLight GBMは、決定木の難点である過学習(=既知のデータにだけ強いモデルを作ってしまい、未知のデータには弱く予測をはずしてしまう)の問題を解決します。
また、何と言ってもこの分析のすごいところが、データの前処理が不要であるという点です。すなわち、Home Creditのデータも、このLight GBMにぶちこんでしまえば、欠損への対処や数値変換なしに予測モデルが作れてしまう、ということです。
そのほかの特徴として、Light GBMは2016年にマイクロソフトが開発したアルゴリズムとなります。直列処理や分割基準の探索方法を工夫することで、計算量を少なくし、処理速度を上げることに成功しています。
勾配ブースティングには、XGboostやCatboostなど、Light GBMより処理速度は遅く、欠損の前処理も必要だが、場合によってはLight GBMより予測精度がよく、予測が早くなる手法もあります。データの特性に合わせてどの手法がよいか検討されるのがおすすめです。
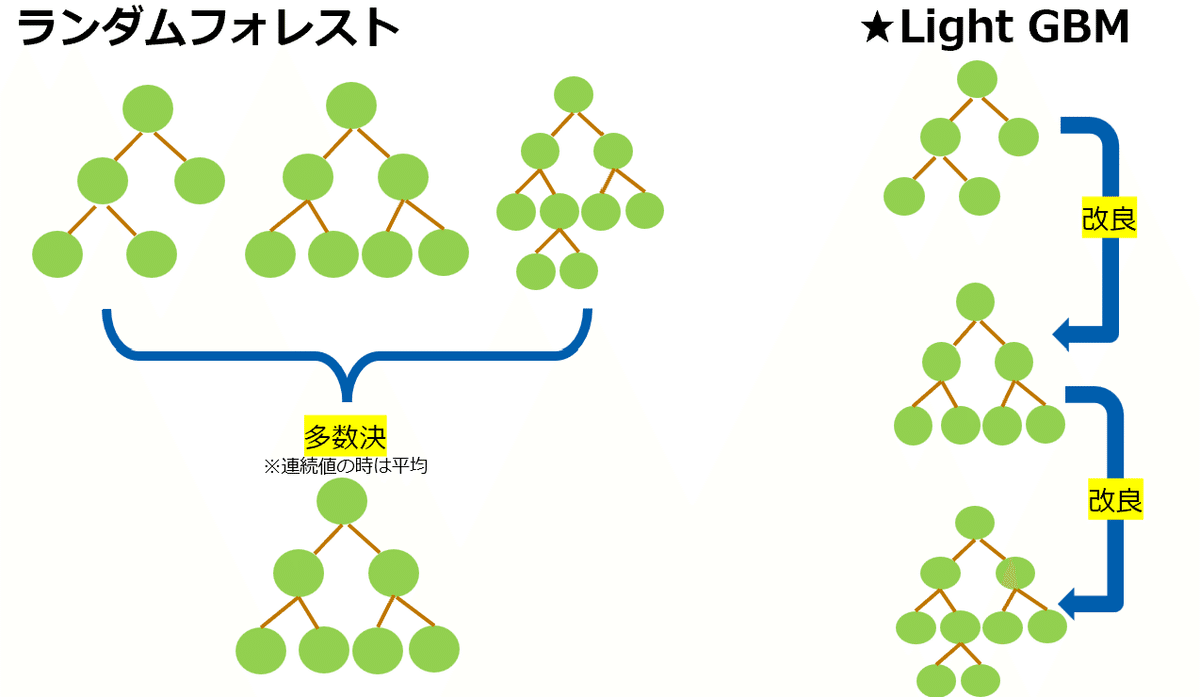

さて、Light GBMの特徴を整理しましたが、いかがでしょうか?
日々の業務の中で「○○を予測したいんだけど、精度の高い予測モデルをパパっと作っちゃって!」といった四方八方からのご要望に、頭を悩ますデータサイエンティストは多いかと思いますが、Light GBMはその問題を解決してくれます。すばらしい恩恵ですね。
Light GBMのモデルをつくってみよう!
では早速、Home Creditのデータで実際にLight GBMをやってみましょう。
コードは以下で実施します。
#元のやつ
lgb_train = lgb.Dataset(X_train, label=y_train)
lgb_valid = lgb.Dataset(X_valid, label=y_valid, reference=lgb_train)
params = {
"boosting_type": "gbdt",
"objective": "binary",
"metric": "auc",
"max_depth": 3,
"num_leaves": 31,
"learning_rate": 0.05,
"feature_fraction": 0.9,
"bagging_fraction": 0.8,
"bagging_freq": 5,
"n_estimators": 1000,
"verbose": -1
}
gbm = lgb.train(
params,
lgb_train,
valid_sets=lgb_valid,
callbacks=[lgb.log_evaluation(50), lgb.early_stopping(10)]
)18行目にgbmとありますが、これが作成したLight GBMのモデルになります。
Light GBMの精度を確認しよう
指標1:AUC
では、機械学習モデルの優れた評価指標の一つであるAUCをみてみましょう。
Home Creditのデータは、予測するものが「履行=0, 不履行=1」の2値で、分類データと呼ばれます。一般的に0は陰性(negative)、1は陽性(positive)と呼ばれます。
2値分類のタスクでは、手元にある実際のデータとモデルを作成した後の予測値で、結果が4つのマトリクス(混同行列)で表現されます。AUCは実際に陽性だったもののうち、陽性と予測したもの(True Positive: TP)、実際に陰性だったもののうち、陽性と予測したもの(False Positive: FP)を面積で表したものになります。
AUCは0.5~1の間をとります。一般的に、0.8以上でよいといわれいて、0.7とかだといいけどほかにもモデルを見直すところがありそう、0.6以下はよくないモデル、といった感じになります。
今回コンペで競う指標は、この後ご説明するGini stabilityになりますが、分類モデルを作った際は、予測モデルを評価する必要があるので先に AUC で評価しました。
では、以下を実行します。
#最高値 0.8こえたい
for base, X in [(base_train, X_train), (base_valid, X_valid), (base_test, X_test)]:
y_pred = gbm.predict(X, num_iteration=gbm.best_iteration)
base["score"] = y_pred
print(f'The AUC score on the train set is: {roc_auc_score(base_train["target"], base_train["score"])}')
print(f'The AUC score on the valid set is: {roc_auc_score(base_valid["target"], base_valid["score"])}')
print(f'The AUC score on the test set is: {roc_auc_score(base_test["target"], base_test["score"])}') 〇_train, 〇_valid, 〇_testとあるかと思いますが、
これはモデルの精度をはかるためにデータを分割している状態です。
イメージとしては、以下のような形です。

現時点で手元にあるデータを分割し(今回は、trainデータ:testデータ = 6:4)trainを予測モデルの作成に、残りのtestデータを未知のデータ(将来手に入るデータとみなす)として予測の精度をはかっていきます。
※validデータは使用しないことも多いのですが、ひとつ前のコードにでてきたparamsの調整に使用します。
また、以下がコードを実行した結果です。

結果の解釈として、trainで0.764、testで0.748ということで結果はまずまずですが、もう少しモデルの改善の余地がありそうと言えます。
指標2:Gini stability
一方、今回のコンペで競う指標となっているGini stabilityです。
Gini stabilityの算出には以下の2点が必要です。
Gini係数:顧客の契約経過期間(WEEK_NUM)ごとに、求めたAUCを2倍して1から引いたもの
回帰係数(a):WEEK_NUMごとのGini係数に対して、回帰直線を作成したときの回帰モデルの傾き
これらを使用し、aの傾きが-になるとGini係数のモデルの予測性能が低下している=ペナルティとみなして、Gini stabilityの計算に反映されます。
では、Gini stabilityのコードと結果を確認しましょう。
def gini_stability(base, w_fallingrate=88.0, w_resstd=-0.5):
gini_in_time = base.loc[:, ["WEEK_NUM", "target", "score"]]\
.sort_values("WEEK_NUM")\
.groupby("WEEK_NUM")[["target", "score"]]\
.apply(lambda x: 2*roc_auc_score(x["target"], x["score"])-1).tolist()
print(sorted(gini_in_time))
x = np.arange(len(gini_in_time))
y = gini_in_time
a, b = np.polyfit(x, y, 1)
y_hat = a*x + b
residuals = y - y_hat
res_std = np.std(residuals)
avg_gini = np.mean(gini_in_time)
return avg_gini + w_fallingrate * min(0, a) + w_resstd * res_std
stability_score_train = gini_stability(base_train)
stability_score_valid = gini_stability(base_valid)
stability_score_test = gini_stability(base_test)
print(f'The stability score on the train set is: {stability_score_train}')
print(f'The stability score on the valid set is: {stability_score_valid}')
print(f'The stability score on the test set is: {stability_score_test}') #testあげないとだめまず前提としてGini stabilityはKaggle特有の指標になります。Gini係数や回帰係数(a)については一般的に使用される指標ですが、Gini stabilityはその点が異なるので注意しましょう。

結果の解釈として「これ以上だといい」というような基準がないため、ほかの参加者と相対的に比較することになります。
現状の結果は0.45以上となりましたが、上位のスコアは0.6台であり、この結果からも、現段階ではまだモデル作成のアイデアや工夫が必要そうだといえます。

【コーヒーブレイク ー Gini stabilityの計算式のはなし ー】
Gini stabilityの計算式について、値が負の場合にはさらにaの傾きに×0.88の重み付けがされるのですが、「Gini stabilityの精度が上がりにくいのはなぜか、0.88とは何なのか、重み付けとして数値が高すぎるのではないか」と我々は疑問でした。
Kaggleではコンペについて意見を述べたり、参加者たちと意見交換できる「ディスカッション」という場があるのですが、この点について議論があり「この計算方法で適切に時間の経過に対するモデルの性能をはかれるのか?」といった参加者からの声も上がっています。(熱い、、)
7.前編のまとめ
いかがでしたでしょうか?Kaggleというコンペについて、敷居の高いイメージをもってらっしゃる方も多いかと思います。
今回は、読んでくださっている皆さまに、コンペやデータ分析に少しでも親近感をもっていただいたり、抵抗感をなくしていただけるよう、参加したコンペや分析について、数式なし・図をメインに解説させていただきました!
また今回の内容は、機械学習の基礎的な部分もありました。後編では少し難易度を上げて(ただしどなたでも理解できることを目標に)、Kaggleで筆者が挑戦した「欠損補完」と「データ不均衡の対策」のお話をさせていただきます!
ここまで読んでいただき、ありがとうございます!