

データ利活用の可能性を広げる連合学習

連合学習とは
概要
連合学習とは、分散機械学習の手法であり、クライアント側の複数デバイスが個別に持つデータを活用してモデルを学習する方法です。各デバイスは自身のデータを用いて学習を行い、その結果を集約することで共同のモデルを構築します。デバイスからデータを外部に提供しないことで、データのプライバシーを保護しながら、より多様なデータを利用できるため、モデルの精度向上や汎化性能の向上が期待できます。連合学習は、医療データやプライベートな情報を含むデータの利用において、プライバシーを保護しながら協力的な学習が可能になります。
日本語で広義の「連合」は、ある同じ目的を持った2つ以上の組織または個人が、それぞれの枠組みを維持したまま結びつくための新たな1つの組織を形成することであり、皆で手を取り合って共に同じ何かを成し遂げる様子を想像されると思います。
しかしながら、参加者間で情報やリソースの共有など、オープンな関係性をもつ傾向にある「連合」とは違い「連合学習」ではデータを参加者間で共有しません。
背景
従来の機械学習では、データを一つの場所に集めて集中的に学習を行っていますが、データのプライバシーやセキュリティの懸念があります。また、大規模なデータセットの移動や処理には時間とコストがかかるため、効率的な学習が難しいとされています。これらの問題を解決する一つの手段として連合学習が開発されました。
連合学習の手法(フロー)

①まず、参加者がそれぞれのローカル環境でデータセットを準備します
②各参加者がローカルでモデルのトレーニングを行い、モデルを最適化します
③モデルの特徴を表すパラメータを中央サーバーに送信し共有します
④中央サーバーが送付されたパラメータを統合し、新たな共通のパラメータを作成します
⑤統合されたパラメータを参加者に配布して再度②以降の手順を実施します
⑥これらの手順により、モデルが一定の精度や性能に収束したら終了します
要素技術
データプライバシー保護技術
データの暗号化、匿名化、差分プライバシー、データ分散などの手法により、連合学習の参加者が保持するデータを保護しています。
モデルアグリゲーション技術
異なるデバイスやシステムから収集したモデルを組み合わせてより良いモデルに更新します。これには、パラメータの平均化、重み付け、フェデレーテッドアルゴリズムなどが含まれます。
通信効率化技術
デバイスやシステム間での通信が頻繁に行われるため、通信量や通信時間を削減する必要があります。例えば、圧縮アルゴリズム、分散合意プロトコルなどが使用されます。
セキュリティ技術
モデルやデータのセキュリティが重要になるので、不正アクセス、モデルの改竄、データ漏洩などのリスクに対処します。これには、暗号化、データフィルタリング、トラステッドコンピューティングなどが含まれます。
連合学習のメリット/デメリット
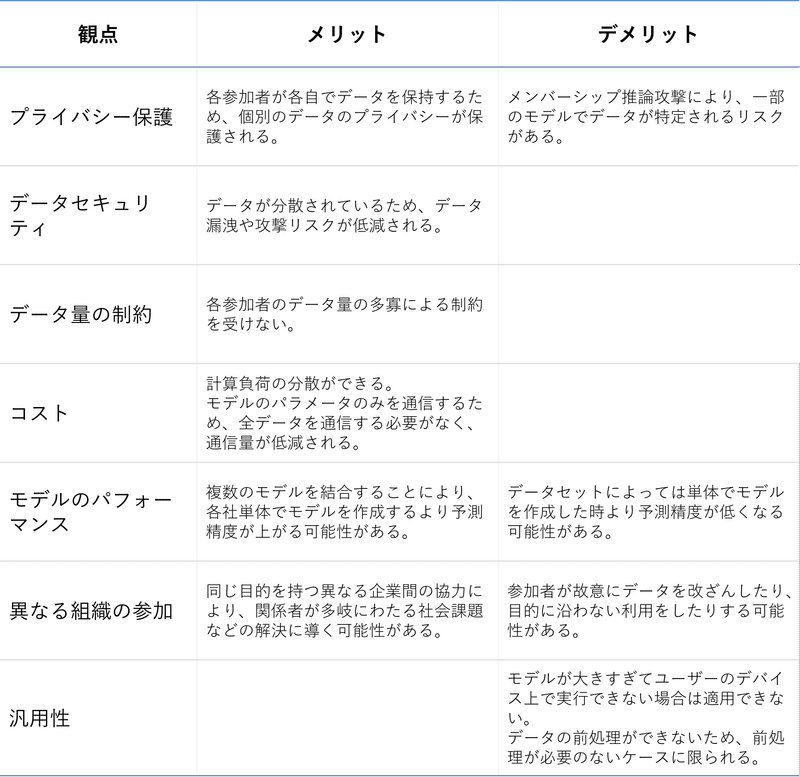
連合学習への期待と課題
連合学習が実用化されることで、データを分散したまま大規模な学習モデルを利用することができるため、個別のプライバシーが保護された状態で、高品質な予測やそれを用いたサービスを提供できると期待されています。
一方で、複数の組織間でのデータの連携や共有に関わる調整が必要であり、実装や評価の困難さが課題としてあります。また、技術の進化に追いつくための規制やガイドラインの策定、倫理的な問題に対する対応が求められます。
未来像(連合学習が消費者にもたらす変革の可能性)
連合学習が今後、私たちの生活にどのような変革をもたらすか、その未来像の一部を紹介します。今までは個人情報の授受がネックとなり分析できなかったものが分析できるようになることで、消費者の生活にメリットをもたらすと考えられています。
・医療分野では、医療機関同士がデータを協力することで、希少な病症の検出精度の向上や効果のある処置の予測等が期待でき、病気の早期発見や治療の最適化につながると考えられています。また、予防医学として疾患リスク予測や最適な運動管理など、未病の改善や健康管理にも活用し、人々がより健康な状態で長生きできるようになると期待されています。
・教育分野では、教育機関や教育研究者が、学生の学習データのモデルを共有することで、個別の学習進度や、ニーズに合わせた教育システムを共同で構築できるようになります。これにより、個々の学生に最適な教育体験を提供することができるようになります。
・環境問題の解決に向けた取り組みでは、国や地域、研究機関、NGOなどのさまざまな関係者が別々に保有している気候変動のモデリングや、環境監視のための学習モデルを統合することで、地球規模での環境予測や持続可能な政策の策定に活用することができます。
活用事例
日本国内では現時点でまだ目立った実用事例がありませんが、海外では既に実用化が始まっています。以下に代表的な海外での実用化例と、日本国内でも始まっている実証事例をご紹介します。
実用事例
IT
〇キーボード予測変換(Google)
Googleのスマートフォンキーボードアプリ「Gboard」では、ユーザーの個人データを保護しながら、連合学習を活用してキーボードの予測機能を改善しています。各ユーザーのデバイス上で学習が行われ、集められた情報は暗号化されて安全に集約されます。
医療
〇医療カルテデータ(Owkin)
患者の病理データや遺伝子データなどを持つ複数の病院と連携し、病気の治療予測モデルを構築しています。各病院のデータはプライバシーを保護しながら、分散されたままで学習が行われ、結果のモデルが共有されます。これにより、より正確な予後予測や治療戦略の開発が可能になると期待されています。
実証事例(日本国内)
金融
〇不正送金検知
複数の銀行によるハイブリッドモデル(不正送金検出の個別学習モデルと連合学習モデルの組み合わせ)を使用することで、一銀行の個別学習モデルでは検知できなかった不正送金の被害取引の検知ができました。また、個別学習モデルよりも早いタイミングで不正口座の検知ができました。
医療
〇創薬(新薬の開発)
連合学習によって機密性の高い医薬品などの化合物データを直接共有せずに、AIモデルの構築と統合を行い、企業や組織間の連携を可能にしました。
この実証では連合学習を活用した上に秘密計算技術を適用し、その精度を検証したものになりますが、他のプライバシー保護技術との親和性も実証されています。
トッパンの取り組み
トッパンでは、「DATuM IDEA」という製薬会社向け電子カルテデータ分析ツールの開発や、店頭プロモーションをしながら購買行動データを取得し、企業の効果的な店頭プロモーションを支援する「リアルDATAサイネージ®」など個人情報を取得するサービスを数多く提供しています。
これらのサービスを提供する際の一つの障壁として「個人情報の取得・保管など含めた取り扱い」があります。
トッパンとしては「ビジネスを推進するための個人情報の取り扱い」ではなく、「ユーザーやデータ提供者の皆さまが、安心してサービスを利用できるようになるための個人情報の取り扱い」を目指して、プライバシー保護技術について研究・開発を行っています。
現時点では、データの利活用の面で「連合学習」を適用しているサービスはありませんが、今後、より良いサービス提供や個人情報の保護を目指し、技術単体だけでなく複合的にプライバシーを保護する技術を活用できるよう、取り組みを強化しています。
トッパン有識者コメント

DXデザイン事業部 技術戦略センター
企画・開発本部 TrustedWeb技術戦略室
ビジネスへの活用や社会課題を解決するために、有益なデータが自由に流通することは価値がある一方で、データに含まれる個人のプライバシーへの配慮も重要な要素です。当社では、上記社会を実現するために、世界的に取り組みが実施出来る技術と捉えています。
連合学習が持つ「モデルデータの推測される可能性」という課題に対し、既に検証を進めている他のプライバシー保護技術である「秘密計算」や、データにノイズを加え個人を推測困難にしながら、元データの分析結果と同じような出力が得らえる「差分プライバシー」を用いて対応する手法もあるため、こうした手法の社会実装に向けた取り組みも行っていきます。
■編集者

DXデザイン事業部 技術戦略センター
企画・開発本部 TrustedWeb技術戦略室